Mini CTF by Anthropic @ BSidesSF
It all started on this one lazy Sunday. I was scrolling through the group chat for the latest batch of The Innovation Lab at PES University (a lively space for current and former members of my university’s nerdiest club), when one of my friends (find him at rowjee.com!) shared a link to a Capture The Flag (CTF) challenge. I’m not sure why this one caught my eye, since I’d never actually participated in a CTF before, but it did.
The Beginning
https://anthropic-at-bsides.com
Starting off, the website looked interesting. Minimalistic, but interesting. It felt intuitive that there’d be something hidden in the Developer Tools options, like the displayed HTML or other source files. I started poking around, and it didn’t take me too long to find ‘stego.png’ in the website’s source. Perhaps a little on-the-nose, but hey :D

You may want to switch to light mode to get a better sense of what the image looks like.
Down to bee-siness
So I went down the Google rabbithole of image steganographic tools, eventually landing up at the conclusion that zsteg was my best bet. A little bit of setup later, zsteg recovered the following information:
b1,a,lsb,xy .. text: "According to all known laws of aviation, there is no way a bee should be able to fly.\nIts wings are too small to get its fat little body off the ground.\nThe bee, of course, flies anyway because bees don't care what humans think is impossible.\nYellow, black"
I, a muggle, had no idea what this was referring to, but it was clearly something. I later learnt that the bee movie script is somewhat of a meme; it appears in comment sections, Tumblr posts, and Reddit comments like a digital ghost. The opening monologue, “According to all known laws of aviation, there is no way a bee should be able to fly,” has apparently become a sacred, nonsensical text for the Extremely Online.
I tried a bunch more steganography tools - zsteg, online ones.. I read up on common steganographic techniques like using strings, examining metadata, and a host of other things. At one point, I gave up and just threw the entire thing at Claude.
This, I’ll admit, started poorly. When I asked for a summary, Claude gave me a perfect, well structured synopsis. It correctly identified Barry B. Benson, his lawsuit against the human race, and the themes of cooperation and respecting nature. It was basically an A+ book ((animated) movie?) report.
Okay, so it knew the plot.. not what I wanted. (Side note - it did really make me want to actually watch the Bee Movie.)
I tossed it a simple follow-up: “is there anything weird about the script?”
..welp.
Claude, in its infinite AI wisdom, proceeded to explain to me why the plot of a movie about talking bees might be, and I quote, “bizarre and nonsensical.” It listed, with the deadpan seriousness of a rocket scientist explaining gravity, that bees probably can’t talk, sue humans, or fly jet airliners.

I promise you this is not doctored.
I stared at the screen, blinked, and realized I was having a conversation with the most literal film critic on the planet. “A bee is depicted flying a jet airliner,” Claude noted, “which is completely fantastical.” Ya don’t say, Claude. Thank you for that groundbreaking analysis.
Upon a slight re-steer, however, Claude uncovered something that there’s no way I could’ve done myself:
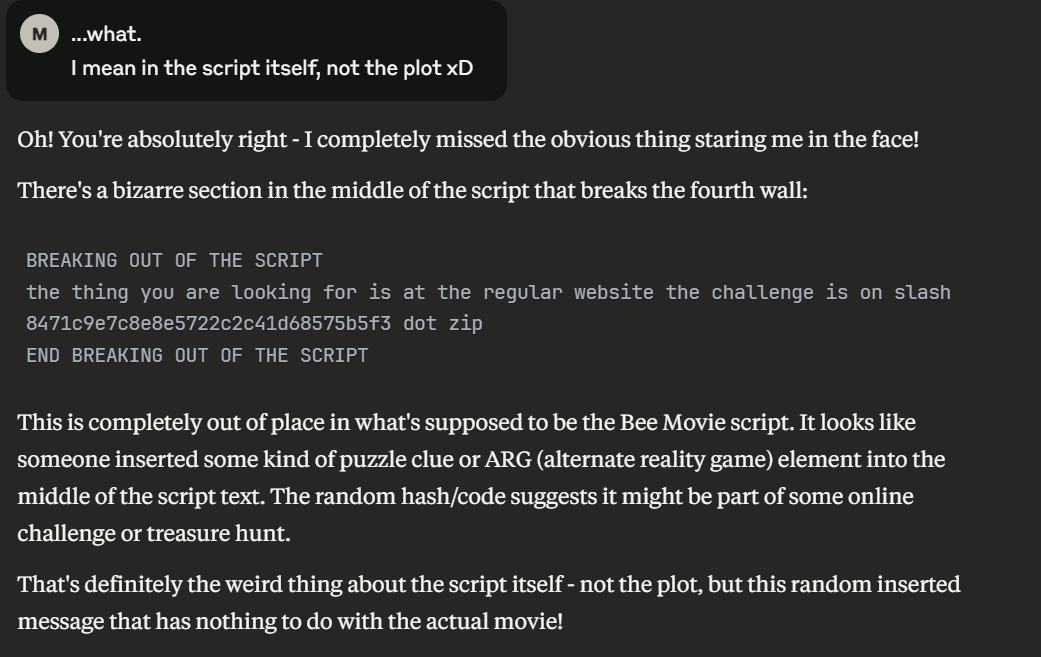
Perhaps if I was more up to date with the zeitgeist, I'd have known to feed it to an LLM a little earlier, but oh well.
What I was looking for was:
BREAKING OUT OF THE SCRIPT
the thing you are looking for is at the regular website the challenge is on slash
8471c9e7c8e8e5722c2c41d68575b5f3 dot zip
END BREAKING OUT OF THE SCRIPT
This was a fairly straightforward instruction - I just had to hit https://anthropic-at-bsides.com/8471c9e7c8e8e5722c2c41d68575b5f3.zip.
Some nice training data
After downloading and extracting that zip file, I was left with a README, model.pkl, and model.py. The README contained the following instructions:
So you did some steganography cracking, huh? Nice job.
The next and final part of this puzzle relies on some understanding of simple multilayer perceptron behaviors. The other file in this ZIP archive is a Python Pickle file that contains a PyTorch model:
The model has been trained to just repeat any lowercase ASCII you give it Except it has also been trained to output a special “flag” given the right password The input to the model is one-hot encoded and shaped (B, N, V) where:
B is the batch size N is the length of the sequence (which is stored in seq_length) V is the vocabulary size (this dimension contains the one-hot encoding)
Your goal is to reverse engineer, crack, or otherwise manipulate the model to extract the password.
While I’ve never actually formally reverse engineered anything before, I’ve always been a fan of exploits, backdoors and what we call ‘jugaad’s back home. The thing is, however, I’m not particularly a machine learning expert. While I have a publication related to Bioinformatics and leveraging tabular data and ML, I didn’t have a theoretically foundational understanding of ML - just an applied one. But perhaps that’s a good thing.
Like the README says, the model is trained to output the same lowercase ASCII string that it is given as input. The model.py was just:
import torch
import torch.nn as nn
import string
vocab = " " + string.ascii_lowercase
class ASCIIModel(nn.Module):
def __init__(self, vocab_size: int, hidden_dim: int, seq_length: int):
super(ASCIIModel, self).__init__()
self.vocab_size = vocab_size
self.seq_length = seq_length
self.final = nn.Linear(seq_length * vocab_size, vocab_size * seq_length)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x.view(-1, self.seq_length * self.vocab_size)
logits = self.final.forward(x)
logits = logits.view(-1, self.seq_length, self.vocab_size)
return logits
Alright, so it’s a very basic linear Multi-Layer Perceptron (MLP), with only one hidden layer, where each input sequence of characters is just a sequence of one-hot encoded vectors. Makes enough intuitive sense.
Trying to run it once tells us that all inputs must be 32 characters in length, since the dimensions must multiply to 864 (or you get an error). Essentially, a 32x27 input matrix. (In case you didn’t catch it, 27 is the ‘vocabulary size’ - a to z, and a space.)
This means that I need a little function to actually one-hot encode my inputs. No biggie:
def encode_input(input_text)
one_hot = torch.zeros(32, len(model.vocab))
for i, char in enumerate(input_text): # input_text is my lowercase ascii input
char_idx = model.vocab.index(char)
one_hot[i, char_idx] = 1
return one_hot
Now it’s time to actually run the model:
import torch
import torch.nn as nn
import string
import pickle
import model # the model.py file
model = torch.load("./model.pkl", weights_only=False)
input_string = 'hello world'
input_tensor = encode_input(input_string)
output = model(input_tensor)
print(f' Input: {input_string}')
print(output)
Oh wait, the output is a matrix again! It’s essentially ’logits’, or raw output describing the likelihood (informally) of each possible letter at each position in the 32 character output.
Applying a ‘softmax’ function over the output would convert the logits into a set of values normalised to form a probability distribution. The normalisation means that the probabilities sum up to ‘1’. The softmax isn’t strictly necessary in this scenario, but since we’re all about good practices, I added it anyway.
probabilities = torch.softmax(output, dim=2)
output_string = ''.join([model.vocab[i] for i in probabilities[0].argmax(dim=1).tolist()])
''' The argmax gives us the index of the highest value - in our case, the index with the highest probability, and hence, the most likely letter preduicted'''
print(f'Output: {output_string}')
Interestingly, this is what I saw:
Input: hello world
Output: hello worldn gmc traiwing data
We were already getting somewhere! I then tried pasting the vocab string verbatim (" abcdefghijklmnopqrstuvwxyz"), which gave me ‘flag is damn nice training’. I thought I had it! But something felt off; the flag didn’t make enough sense. So I tried a few more inputs, but that’s about the best I could get - clearly, I had to try something else.
After spending a while trying to find anomalies in the weights of the model (and having no success), an idea sauntered into my head. This was a basic, single-hidden-layer MLP. It’s very likely that for a model like this, trained to parrot its input, had to be generally biased towards the ‘special output’ in some way for it to give that special output for a ‘password’.
In practice, that means that it was likely that the ‘second most likely letter’, ’third most likely letter’ and so on held answers. And so I set out, looking at the 2nd most probable outputs for each input character for a bunch of strings:
def get_nth_choice_indices(model_obj, one_hot, nth_index):
logits = model_obj(one_hot)
probabilities = torch.softmax(logits, dim=2)
nth_idxs = probabilities.topk(2, dim=2).indices[0, :, nth_index-1]
return nth_idxs
vocab = model.vocab
V = model_obj.vocab_size
seq_len = 32
num_samples = 5000
counts = [[0]*V for _ in range(seq_len)]
for _ in range(num_samples):
input_text = ''.join(random.choice(vocab) for _ in range(seq_len))
one_hot = torch.zeros(1, seq_len, V)
for i, ch in enumerate(input_text):
idx = vocab.index(ch)
one_hot[0, i, idx] = 1
second_idxs = get_nth_choice_indices(model_obj, one_hot, 2)
for pos, letter in enumerate(second_idxs.tolist()):
counts[pos][letter] += 1
best_second_indices = [max(range(V), key=lambda letter: counts[pos][letter]) for pos in range(seq_len)]
print(''.join(vocab[i] for i in best_second_indices))
et voila, the output was
flag is damn nice training data
Damn; nice training data!
That’s a wrap!
The final flag was indeed ‘damn nice training data ‘. While I might not have found the intended “password,” I had found the flag; that counts!*
And that’s that - an awesome way to spend a Sunday afternoon and a brilliant intro to how much fun the world of cybersecurity and reverse engineering can be. I’m already looking forward to the next challenge, and I might just start doing more CTFs! A huge thank you to Ziyad Edher (https://www.ziyadedher.com/) for creating such a fun and engaging mini-CTF (and the 500$ worth of Claude API credits!). Perhaps one day our paths will cross again :D.
PS: I was actually able to recreate this MLP and its behaviour! You can read about that in my post about making an undergraduate level pseudo-CTF here.
* I did learn way later that you actually could recover the ‘password’ from the flag, by further ’training’ the model but using the negative of the loss function when propagating the gradients. Who’da thunk?